ユーザーデータの保持にはFirestoreが便利だが、そのデータを様々な形で集計したい場合は、BigQueryに連携する方法が一般的にあるようだったので、メモ
Firestoreでも簡単な集計は実行できるようだが、BigQueryの方が複雑な集計にも対応できるので、集計は主にBigQueryで行いたい、というモチベーションが発生した。
Firebase Extensions Hubから、以下の拡張機能をインストールする
https://extensions.dev/extensions/firebase/firestore-bigquery-export
Firebase Extensionsにも同様のものがある。Firebase Extensions Hubからのインストールと同じ挙動になると思われる: https://firebase.google.com/products/extensions?hl=ja
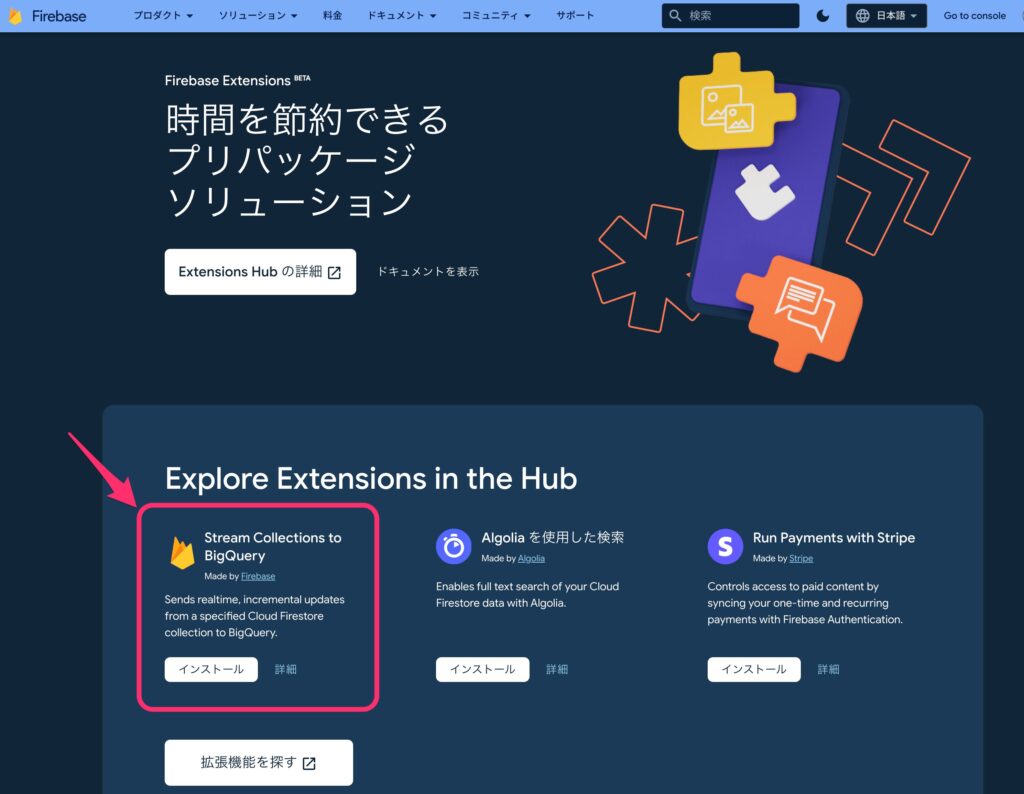
同一の拡張機能を表す文字列の表記揺れが激しい。どういう事情があったのか気になるところ。
- Stream Firestore to BigQuery (Firebase Extensions Hub での表記)
- Stream Collections to BigQuery (Firebase Ectensionsでの表記)
- firestore-bigquery-export (firebase CLIでの表記)
インストール完了までの流れは以下です。
- いずれかの画面から拡張機能のインストールボタンを押す
- インストール先のFirebaseプロジェクトの選択画面に映るので、選択。
- プロジェクト名等設定しながら進める。(以下の「設定について」を参照)
- 5分程度待つとインストールが完了する
設定について
設定項目の多くはデフォルト値でも動作しますが、少なくとも以下の項目は適切に値を設定する必要があるので注意。
- BigQueryのプロジェクトID(デフォルト: FirebaseのプロジェクトID)
- BigQueryに連携するFirestoreのコレクション名(デフォルト: posts)
- BigQuery側に生成されるテーブル・ビューの名前の接頭辞(デフォルト: posts)
インストール後、動作確認のためにFirestoreへドキュメントを追加/削除して、BigQuery側に連携されることを確認する手順が示されるのでやってみましょう。(必須ではない。)
この時点で、BigQuery側に生成済みのものは以下であることを覚えておいてください。
- プロジェクト
- データセット
- テーブル
- データセット
- データセット
BigQueryでは以下のように表示されます。
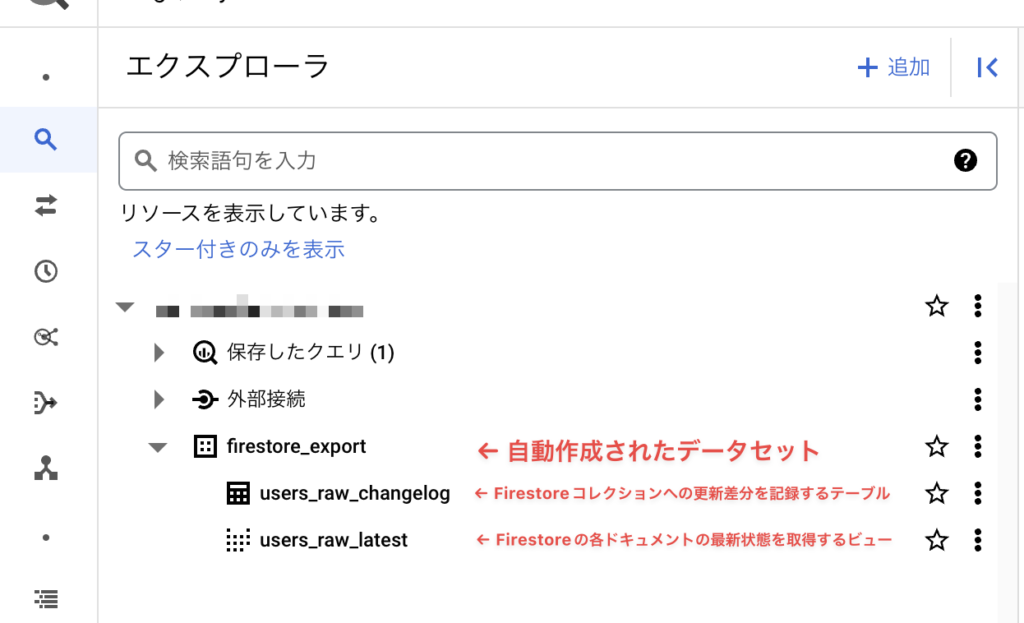
BigQueryに連携するFirebaseコレクションが未作成の場合は、この時点で作成してください。
以下の手順で、Firestoreドキュメントに変更が起きた場合の動作を確認できます。
ドキュメント追加
コレクションに適当なドキュメントを作成する。
(チュートリアルでは bigquery-mirror-test というドキュメントIDで作る、という説明になっている。)
Google Cloud Platform コンソールの BigQuery Web UI に移動する。
xxxの部分は、インストール時にBigQuery用のprefixとして指定した値です。
# 差分確認クエリ
SELECT * FROM `プロジェクト名.firestore_export.xxx_raw_changelog`
# 最新ビュー確認クエリ
SELECT * FROM `プロジェクト名.firestore_export.xxx_raw_latest`クエリを使わずに、テーブル、ビューのプレビュー機能を使ってもOKです。
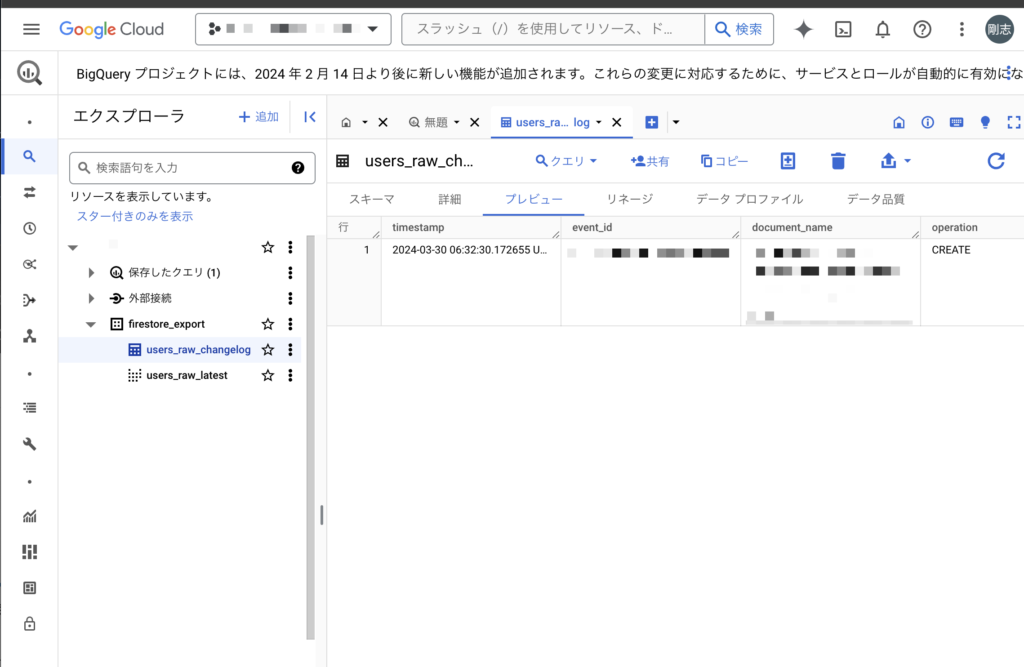
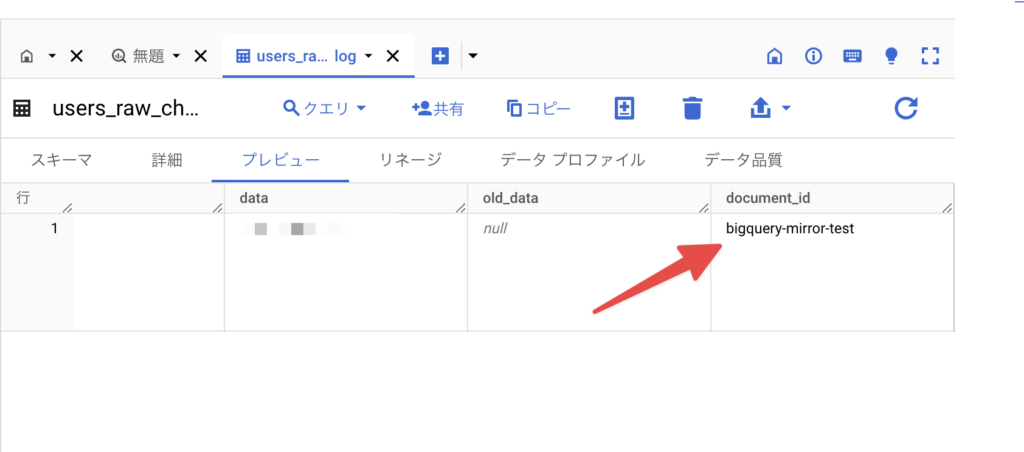
差分確認クエリの実行時に、xxx_raw_latest(xxxは拡張機能インストール時に設定した接頭辞)から、最新のレコードをクエリします。先ほど追加したレコードが表示されればOKです。
SELECT * FROM `プロジェクト名.firestore_export.xxx_raw_latest`ドキュメント更新
(公式チュートリアルには書いていません。)
- ドキュメントのフィールドを修正
- 差分確認クエリにより、該当ドキュメントへのoperation=UPDATEのレコードが追加されていることを確認
- 最新ビュー確認クエリにより、該当ドキュメントのdataが最新の値になっていることを確認
ドキュメント削除
- ドキュメントを削除
- 差分確認クエリにより、該当ドキュメントへのoperation=DELETEのレコードが追加されていることを確認
- 最新ビュー確認クエリにより、該当ドキュメントがなくなっていることを確認
公式ドキュメントでは、以下のクエリでドキュメントを対象に実行された処理をchangelogから確認する方法が記載されている。
SELECT *
FROM `プロジェクト名
ここまでで連携設定は完了したので、以降Firesotreに追加されるドキュメントはBigQueryに連携されるようになる。しかし、Firestoreの既存のドキュメントが自動で連携されるわけではない。
Firebaseの既存ドキュメントをBigQueryにインポートするためのCLIが存在するので、必要に応じて使う。質問に答えていくだけで使えてお手軽。
https://www.npmjs.com/package/@firebaseextensions/fs-bq-import-collection
実行の前に、CLIでGCP側の認証を通しておく必要があるので、以下を実行。
# GCPの認証
gcloud auth loginインポートのためのコマンド実行の雰囲気は以下。質問が次々に与えられるので、適切に回答していくだけ。
❯ npx @firebaseextensions/fs-bq-import-collection
? What is your Firebase project ID?
# FirebaseのプロジェクトID
? What is your BigQuery project ID?
# BigQueryのプロジェクトID
? What is the path of the the Cloud Firestore Collection you would like to import from? (This may, or may not, be the same Collection for which you plan to mirror changes.)
# インポートしたいFirebaseのコレクション名
? Would you like to import documents via a Collection Group query?
# よくわからなかった
? What is the ID of the BigQuery dataset that you would like to use? (A dataset will be created if it doesn't already exist)
# BigQueryの保存先のデータセット名。先ほどインストールしたFirebase拡張のものと合わせる。インストールする際にデフォルト設定で進めていた場合、firestore_exportとなる。
? What is the identifying prefix of the BigQuery table that you would like to import to? (A table will be created if one doesn't already exist)
# BIgQueryのデータセット内に用意するテーブル、ビューの名前の接頭辞
? How many documents should the import stream into BigQuery at once?
# インポートの流量。デフォルトの300で良さそうだが、データ量多ければ大きくして良い
? Where would you like the BigQuery dataset to be located?
# BigQueryデータセットの「データのロケーション」。東京ならasia-northeast1
? Would you like to run the import across multiple threads?
# yesにしておくと高速に処理されそう
? Would you like to use the new optimized snapshot query script?
# yesにしておくと高速に処理されそう
? Would you like to use a local firestore emulator?
# よくわからなかった
GCP CLIが手元に入っていない場合は、こちらからインストール
https://cloud.google.com/sdk/docs/install?hl=ja#earlier_versions_of_the
BigQueryにレコードを用意できたので、集計してみる。
FirestorteではドキュメントはKVSのような形式で値を保持するが、
BigQueryに取り込まれたテーブル(hoge_raw_changelog という形式の名前になる)では、dataカラムにJSON型で保持される
BigQueryの集計クエリでは、JSONからキー指定で値を取り出すことができる。以下は適当な集計クエリ。
WITH latest AS (
SELECT
max(timestamp) as latest_timestamp,
document_name
FROM
`Firebaseプロジェクト.firestore_export.mid_term_test_raw_changelog`
GROUP BY
document_name
),
extracted_data AS (
SELECT
JSON_EXTRACT(data, '$.uid') AS uid, --- JSONとして取り込まれたデータから、キーを指定して値を取得
JSON_EXTRACT(data, '$.test_id') AS test_id,
JSON_EXTRACT(data, '$.score') AS score,
FROM
`Firebaseプロジェクト.firestore_export.mid_term_test_raw_changelog` AS t
JOIN latest ON (
t.document_name = latest.document_name
AND (
IFNULL(t.timestamp, timestamp("1970-01-01 00:00:00+00"))
) = (
IFNULL(
latest.latest_timestamp,
timestamp("1970-01-01 00:00:00+00")
)
)
)
WHERE
operation != "DELETE"
)
SELECT
uid AS user,
COUNT(*) AS count,
ARRAY_AGG(
STRUCT(
test_id,
score
)
) AS scores
FROM
extracted_data
GROUP BY
uid;